
Homework 9: Neural Networks [200 points]
Instructions
In this assignment, you will implement functions commonly used in Neural Networks from scratch without use of external libraries/packages other than NumPy. Then, you will build Neural Networks using one of the Machine Learning frameworks called PyTorch for a Fashion MNIST dataset. This portion of the assignment will require a lot of reading but significantly less coding, and it takes you on a guided tour of increasingly complex Neural Network architectures.
There are 2 skeleton files as listed at the top of the assignment. You should fill in your own code as suggested in this document. Since portions of this assignment will be graded automatically, none of the names or function signatures in this file should be modified. However, you are free to introduce additional variables or functions if needed.
You will find that in addition to a problem specification, most programming questions also include a pair of examples from the Python interpreter. These are meant to illustrate typical use cases, and should not be taken as comprehensive test suites.
You are strongly encouraged to follow the Python style guidelines set forth in PEP 8, which was written in part by the creator of Python. However, your code will not be graded for style.
Once you have finished the assignment, you should submit both 2 completed skeleton files on Gradescope. You may submit as many times as you would like before the deadline, but only the last submission will be saved.
1. Individual Functions for CNN [100 points]
The goal of this part of the assignment is to get an intuition of the underlying implementation used in Convolutional Neural Networks (CNN), specifically performing convolution and pooling, and applying an activation function. You will design a CNN in Part 2 of this assignment, and although you will not use the methods you implemented here, they will help build your understanding of what you’re asked to do later on.
As mentioned in the instructions, you are restricted from using any external packages other than NumPy. Numpy has a Quickstart tutorial, which we recommend looking at if you are not familiar or would like to refresh memory.
-
[36 points] Write a function
convolve_greyscale(image, kernel)that accepts a numpy arrayimageof shape(image_height, image_width)(greyscale image) of integers and a numpy arraykernelof shape(kernel_height, kernel_width)of floats. The function performs a convolution, which consists of adding each element of the image to its local neighbors, weighted by the kernel after the kernel has been flipped both vertically and horizontally.The result of this function is a new numpy array of floats that has the same shape as the input
image. Apply zero-padding to the input image to calculate image edges. Note that the height and width of bothimageandkernelmight not be equal to each other. You can assumekernel_widthandkernel_heightare odd numbers.There exist a few visualisations hands-on experience of applying a convolution online, for instance a post by Victor Powell. For more information, you can also use real images as an input. We recommend selecting a few images of type
grayfrom the Miscellaneous Volume of the USC-SIPI Image Database. (Image in the third example below is taken from this dataset labelled under 5.1.09.)For the first example below, the convolution starts at
image[0, 0]. A padded version ofimagefor akernelof size(3, 3)would be the following:padded_image = np.array([ [ 0, 0, 0, 0, 0, 0, 0], [ 0, 0, 1, 2, 3, 4, 0], [ 0, 5, 6, 7, 8, 9, 0], [ 0, 10, 11, 12, 13, 14, 0], [ 0, 15, 16, 17, 18, 19, 0], [ 0, 20, 21, 22, 23, 24, 0], [ 0, 0, 0, 0, 0, 0, 0]])From
padded_image, we can compute the first value of theoutput, specificallyoutput[0, 0]. Recall that although we must flip ourkernelvertically and then horizontally in general, our example here has a symmetrical kernel soflipped_kernel == kernel.output[0, 0] = flipped_kernel[0, 0] * padded_image[0, 0] + flipped_kernel[0, 1] * padded_image[0, 1] + ... + flipped_kernel[2, 2] * padded_image[2, 2]Here is the full example for the interpreter:
>>> import numpy as np >>> image = np.array([ [0, 1, 2, 3, 4], [ 5, 6, 7, 8, 9], [10, 11, 12, 13, 14], [15, 16, 17, 18, 19], [20, 21, 22, 23, 24]]) >>> kernel = np.array([ [0, -1, 0], [-1, 5, -1], [0, -1, 0]]) >>> print(convolve_greyscale(image, kernel)) [[-6. -3. -1. 1. 8.] [ 9. 6. 7. 8. 19.] [19. 11. 12. 13. 29.] [29. 16. 17. 18. 39.] [64. 47. 49. 51. 78.]]Observe that the dimensions of the input and the output are equal. Here is another example with a different
kernel.>>> import numpy as np >>> image = np.array([ [0, 1, 2, 3, 4], [ 5, 6, 7, 8, 9], [10, 11, 12, 13, 14], [15, 16, 17, 18, 19], [20, 21, 22, 23, 24]]) >>> kernel = np.array([ [1, 2, 3], [0, 0, 0], [-1, -2, -3]]) >>> print(convolve_greyscale(image, kernel)) [[ 16. 34. 40. 46. 42.] [ 30. 60. 60. 60. 50.] [ 30. 60. 60. 60. 50.] [ 30. 60. 60. 60. 50.] [ -46. -94. -100. -106. -92.]]>>> import numpy as np >>> from PIL import Image >>> import matplotlib.pyplot as plt >>> image = np.array(Image.open('5.1.09.tiff')) >>> plt.imshow(image, cmap='gray') >>> plt.show() >>> kernel = np.array([ [0, -1, 0], [-1, 5, -1], [0, -1, 0]]) >>> output = convolve_greyscale(image, kernel) >>> plt.imshow(output, cmap='gray') >>> plt.show() >>> print(output) [[416. 352. 270. ... 152. 135. 233.] [274. 201. 126. ... 85. 69. 155.] [255. 151. 131. ... 56. 45. 164.] ... [274. 124. 159. ... 91. 176. 241.] [166. 139. 118. ... 122. 156. 280.] [423. 262. 280. ... 262. 312. 454.]]
Left: line 6 (before function invocation)
Right: line 10 (after function invocation) -
[8 points] Write a function
convolve_rgb(image, kernel)that accepts a numpy arrayimageof shape(image_height, image_width, image_channels)of integers and a numpy arraykernelof shape(kernel_height, kernel_width)of floats. The channel dimension represents how many layers of data are avaiable at each coordinate for the image. For a greyscale image, the value ofimage_channelsis \(1\). In an RGB image, this is \(3\): one for red, one for green, and one for blue.The function performs a convolution on each channel of an image, which consists of adding each element of the image to its local neighbors, weighted by the kernel (flipped both vertically and horizontally).
The result of this function is a new numpy array of floats that has the same shape as the input
image. You can useconvolve_greyscale(image, filter)implemented in the previous part to go through each depth of an image. As before, apply zero-padding to the input image to calculate image edges. Note that the height and width of bothimageandkernelmight not be equal to each other. You can assumekernel_widthandkernel_heightare odd numbers.We recommend selecting a few images of type
colorfrom the Miscellaneous Volume of the USC-SIPI Image Database. (Images in the examples below are taken from this dataset labelled under 4.1.07)>>> import numpy as np >>> from PIL import Image >>> import matplotlib.pyplot as plt >>> image = np.array(Image.open('4.1.07.tiff')) >>> plt.imshow(image) >>> plt.show() >>> kernel = np.array([ [0.11111111, 0.11111111, 0.11111111], [0.11111111, 0.11111111, 0.11111111], [0.11111111, 0.11111111, 0.11111111]]) >>> output = convolve_rgb(image, kernel) >>> plt.imshow(output.astype('uint8')) >>> plt.show() >>> print(np.round(output[0:3, 0:3, 0:3], 2)) [[[ 63.67 63.44 47.22] [ 95.56 94.89 70.89] [ 95.56 94.78 70.89]] [[ 95.67 95.22 70.67] [143.33 142.56 105.89] [143.22 142.33 106. ]] [[ 96.33 96.11 70.22] [144.11 144. 105.11] [143.78 143.44 105.22]]]
Left: line 6 (before function invocation)
Right: line 10 (after function invocation)>>> import numpy as np >>> from PIL import Image >>> import matplotlib.pyplot as plt >>> image = np.array(Image.open('4.1.07.tiff')) >>> plt.imshow(image) >>> plt.show() >>> kernel = np.ones((11, 11)) >>> kernel /= np.sum(kernel) >>> output = convolve_rgb(image, kernel) >>> plt.imshow(output.astype('uint8')) >>> plt.show() >>> print(np.round(output[0:3, 0:3, 0:3], 2)) [[[43.26 43.31 31.32] [50.54 50.67 36.6 ] [57.83 58. 41.88]] [[50.64 50.86 36.51] [59.17 59.5 42.65] [67.73 68.1 48.81]] [[58.01 58.49 41.7 ] [67.79 68.41 48.72] [77.6 78.29 55.75]]] Left: line 6 (before function invocation)
Right: line 11 (after function invocation) -
[40 points] Write a function
max_pooling(image, kernel_size, stride)that accepts a numpy arrayimageof integers of shape(image_height, image_width)(greyscale image) of integers, a tuplekernel_sizecorresponding to(kernel_height, kernel_width), and a tuplestrideof(stride_height, stride_width)corresponding to the stride of pooling window.The
stridetuple indicates how many values in each direction to skip between applications of the kernel. If, as in the first example, the inputimagehas a size of \(4 x 4\), then the indices at which the kernel should be applied areimage[0, 0],image[0, 2],image[2, 0], andimage[2, 2].The goal of this function is to reduce the spatial size of the representation and in this case reduce dimensionality of an image with max down-sampling. Max down-sampling selects the largest value in any specified kernel window. For example, starting from
input[0, 0]and akernel_size = (2, 2), thenoutput[0, 0]should be the largest value among any ininput[0:2, 0:2].It is not common to pad the input using zero-padding for the pooling layer in Convolutional Neural Network and as such, so we do not ask to pad. Notice that this function must support overlapping pooling if
strideis not equal tokernel_size.As before, we recommend selecting a few images of type
grayfrom the Miscellaneous Volume of the USC-SIPI Image Database. (Image in three examples below are taken from this dataset labelled under 5.1.09.)>>> image = np.array([ [1, 1, 2, 4], [5, 6, 7, 8], [3, 2, 1, 0], [1, 2, 3, 4]]) >>> kernel_size = (2, 2) >>> stride = (2, 2) >>> print(max_pooling(image, kernel_size, stride)) [[6 8] [3 4]]>>> image = np.array([ [1, 1, 2, 4], [5, 6, 7, 8], [3, 2, 1, 0], [1, 2, 3, 4]]) >>> kernel_size = (2, 2) >>> stride = (1, 1) >>> print(max_pooling(image, kernel_size, stride)) [[6 7 8] [6 7 8] [3 3 4]]>>> import numpy as np >>> from PIL import Image >>> import matplotlib.pyplot as plt >>> image = np.array(Image.open('5.1.09.tiff')) >>> plt.imshow(image, cmap='gray') >>> plt.show() >>> kernel_size = (2, 2) >>> stride = (2, 2) >>> output = max_pooling(image, kernel_size, stride) >>> plt.imshow(output, cmap='gray') >>> plt.show() >>> print(output) [[160 146 155 ... 73 73 76] [160 148 153 ... 75 73 84] [168 155 155 ... 80 66 80] ... [137 133 131 ... 148 149 146] [133 133 129 ... 146 144 146] [133 133 133 ... 151 148 149]] >>> print(output.shape) (128, 128) Left: line 6 (before function invocation with image shape (256, 256))
Right: line 11 (after function invocation with image shape (128, 128))>>> import numpy as np >>> from PIL import Image >>> import matplotlib.pyplot as plt >>> image = np.array(Image.open('5.1.09.tiff')) >>> plt.imshow(image, cmap='gray') >>> plt.show() >>> kernel_size = (4, 4) >>> stride = (1, 1) >>> output = max_pooling(image, kernel_size, stride) >>> plt.imshow(output, cmap='gray') >>> plt.show() >>> print(output) [[160 160 155 ... 75 73 84] [162 160 155 ... 80 76 84] [168 168 155 ... 80 76 84] ... [137 133 133 ... 149 149 149] [133 133 133 ... 149 149 149] [133 133 133 ... 151 149 149]] >>> print(output.shape) (253, 253) Left: line 6 (before function invocation with image shape (256, 256))
Right: line 11 (after function invocation with image shape (253, 253))>>> import numpy as np >>> from PIL import Image >>> import matplotlib.pyplot as plt >>> image = np.array(Image.open('5.1.09.tiff')) >>> plt.imshow(image, cmap='gray') >>> plt.show() >>> kernel_size = (3, 3) >>> stride = (1, 3) >>> output = max_pooling(image, kernel_size, stride) >>> plt.imshow(output, cmap='gray') >>> plt.show() >>> print(output) [[160 155 153 ... 100 76 73] [160 155 153 ... 113 82 73] [162 155 157 ... 118 82 76] ... [133 133 126 ... 155 148 149] [133 133 131 ... 149 148 148] [133 133 131 ... 146 151 149]] >>> print(output.shape) (254, 85) Left: line 6 (before function invocation with image shape (256, 256))
Right: line 11 (after function invocation with image shape (254, 85)) -
[8 points] Similarly to the previous part, write a function
average_pooling(image, kernel_size, stride)that accepts a numpy arrayimageof integers of shape(image_height, image_width)(greyscale image) of integers, a tuplekernel_sizecorresponding to(kernel_height, kernel_width), and a tuplestrideof(stride_height, stride_width)corresponding to the stride of pooling window.The goal of this function is to reduce the spatial size of the representation and in this case reduce dimensionality of an image with average down-sampling.
Average down-sampling computes an unweighted average value in any specified kernel window. For example, starting from
input[0, 0]and akernel_size = (2, 2), thenoutput[0, 0]should be the average of all values ininput[0:2, 0:2].As before, we recommend selecting a few images of type
grayfrom the Miscellaneous Volume of the USC-SIPI Image Database. (Image in the third example is taken from this dataset labelled under 5.1.09.)>>> image = np.array([ [1, 1, 2, 4], [5, 6, 7, 8], [3, 2, 1, 0], [1, 2, 3, 4]]) >>> kernel_size = (2, 2) >>> stride = (2, 2) >>> print(average_pooling(image, kernel_size, stride)) [[3.25 5.25] [2. 2. ]]>>> image = np.array([ [1, 1, 2, 4], [5, 6, 7, 8], [3, 2, 1, 0], [1, 2, 3, 4]]) >>> kernel_size = (2, 2) >>> stride = (1, 1) >>> print(average_pooling(image, kernel_size, stride)) [[3.25 4. 5.25] [4. 4. 4. ] [2. 2. 2. ]]>>> import numpy as np >>> from PIL import Image >>> import matplotlib.pyplot as plt >>> image = np.array(Image.open('5.1.09.tiff')) >>> plt.imshow(image, cmap='gray') >>> plt.show() >>> kernel_size = (2, 2) >>> stride = (2, 2) >>> output = average_pooling(image, kernel_size, stride) >>> plt.imshow(output, cmap='gray') >>> plt.show() >>> print(output) [[152. 145. 154. ... 65.5 71. 73.5 ] [152.75 145.5 143.25 ... 70.5 68.25 74.25] [160.5 149.5 146.25 ... 71. 62.25 75. ] ... [129. 128.75 125.25 ... 144. 138.25 141.75] [127.75 128. 125. ... 142. 135.75 142.25] [125.5 127.75 130. ... 143.75 141.25 146.5 ]] >>> print(output.shape) (128, 128) Left: line 6 (before function invocation with image shape (256, 256))
Right: line 11 (after function invocation with image shape (128, 128))>>> import numpy as np >>> from PIL import Image >>> import matplotlib.pyplot as plt >>> image = np.array(Image.open('5.1.09.tiff')) >>> plt.imshow(image, cmap='gray') >>> plt.show() >>> kernel_size = (4, 4) >>> stride = (1, 1) >>> output = average_pooling(image, kernel_size, stride) >>> plt.imshow(output, cmap='gray') >>> plt.show() >>> print(output) [[148.8125 149.375 146.9375 ... 68.8125 69.875 71.75 ] [149.5 148. 145.625 ... 69.4375 69.4375 71. ] [152.0625 149. 146.125 ... 68. 67.4375 69.9375] ... [128.375 127. 126.75 ... 140. 139.6875 139.5 ] [126.625 127. 127.1875 ... 140.75 140.9375 140.5 ] [127.25 127.8125 127.6875 ... 140.6875 141.0625 141.4375]] >>> print(output.shape) (253, 253) Left: line 6 (before function invocation with image shape (256, 256))
Right: line 11 (after function invocation with image shape (253, 253))>>> import numpy as np >>> from PIL import Image >>> import matplotlib.pyplot as plt >>> image = np.array(Image.open('5.1.09.tiff')) >>> plt.imshow(image, cmap='gray') >>> plt.show() >>> kernel_size = (3, 3) >>> stride = (1, 3) >>> output = average_pooling(image, kernel_size, stride) >>> plt.imshow(output, cmap='gray') >>> plt.show() >>> print(np.round(output, 5)) [[148.11111 150.88889 149.33333 ... 79.33333 66.66667 69.55556] [150.11111 146.33333 147.55556 ... 85. 70.33333 69. ] [150.33333 144.44444 146.55556 ... 93.44444 73.55556 68.22222] ... [127.88889 125.55556 118.66667 ... 146. 142.22222 138.66667] [126.11111 126.55556 123.77778 ... 143.66667 142.44444 140.22222] [127.88889 128.11111 125.88889 ... 142.88889 143.55556 141.55556]] >>> print(output.shape) (254, 85) Left: line 6 (before function invocation with image shape (256, 256))
Right: line 11 (after function invocation with image shape (254, 85)) -
[8 points] Write a function
sigmoid(x)that accepts an a numpy arrayxand applies an element-wise sigmoid activation function on the input.Recall that the sigmoid function \(S\) is defined such that \(S(x) = \frac{1}{1 + e^{-x}}\).
>>> x = np.array([0.5, 3, 1.5, -4.7, -100]) >>> print(sigmoid(x)) [6.22459331e-01 9.52574127e-01 8.17574476e-01 9.01329865e-03 3.72007598e-44]
2. Neural Network for Fashion MNIST Dataset [95 points]
The goal of this part of the assignment is to get familiar with using one of the Machine Learning frameworks called PyTorch.
The installation instructions can be found here. If you are having difficulty installing it, you might want to try to setup PyTorch using miniconda.
Fashion MNIST Dataset
The dataset.csv we will use is a sub-set of the Fashion MNIST train dataset.
![]()

The dataset contains 20000 28x28 greyscale images, where each image has a label from one of 10 classes:
| Label | Description |
|---|---|
| 0 | T-shirt/top |
| 1 | Trouser |
| 2 | Pullover |
| 3 | Dress |
| 4 | Coat |
| 5 | Sandal |
| 6 | Shirt |
| 7 | Sneaker |
| 8 | Bag |
| 9 | Ankle boot |
-
[5 points] The dataset.csv is a comma-separated csv file with a header ‘label, pixel1, pixel2, …, pixel 784’. The first column ‘label’ is a label from 0 to 9 inclusively, and the rest of the columns ‘pixel1’ … ‘pixel784’ are 784 pixels of an image for a corresponding label.
Your task is to fill in
load_data(file_path, reshape_images), wherefile_pathis a string representing the path to a dataset andreshape_imagesis a boolean flag that indicates whether an image needs to be represented as one dimensional array of 784 pixels or reshaped to (1, 28, 28) array pixels.np.reshape()will be useful here. This function returns 2 numpy arrays, where the first array corresponds to images and the second to labels.Since there are 20000 images and labels in
dataset.csv, you should expect something as follows when the function is called withreshape_imagesset toFalse:>>> X, Y = load_data('dataset.csv', False) >>> print(X.shape) (20000, 784) >>> print(Y.shape) (20000,)And something as follows when the function is called with
reshape_imagesset toTrue:>>> X, Y = load_data('dataset.csv', True) >>> print(X.shape) (20000, 1, 28, 28) >>> print(Y.shape) (20000,)Here is a way to visualise the first image of our data:
>>> import matplotlib.pyplot as plt >>> class_names = ['T-Shirt', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle Boot'] >>> X, Y = load_data('dataset.csv', False) >>> plt.imshow(X[0].reshape(28, 28), cmap='gray') >>> plt.title(class_names[Y[0]]) >>> plt.show()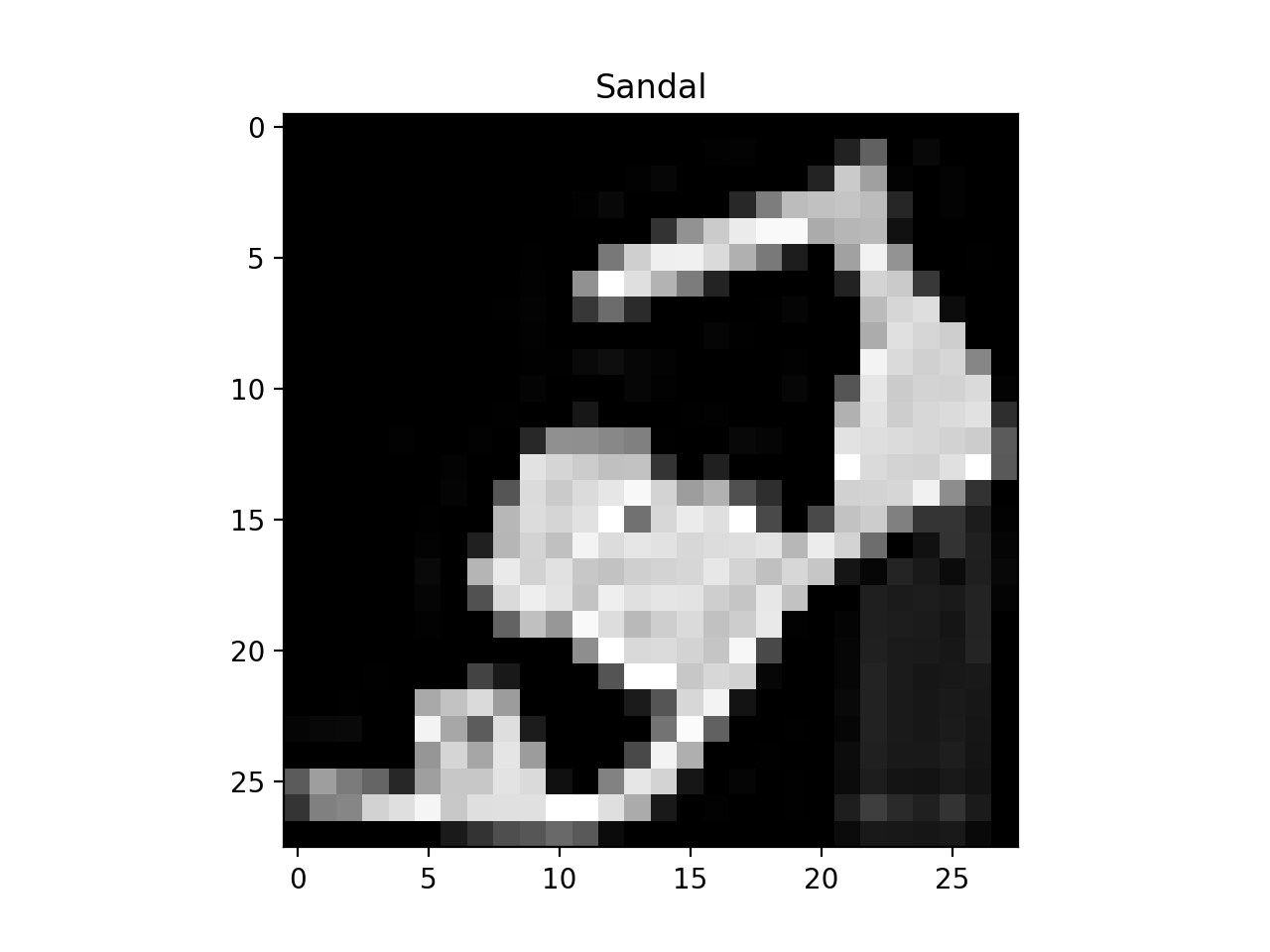
Data Loading and Processing in PyTorch
The
load_data(file_path, reshape_images)function gets called in theFashionMNISTDatasetclass, which is given in the skeleton file. TheFashionMNISTDatasetclass is a custom dataset that inheritstorch.utils.data.Dataset, which is an abstract class representing a dataset in PyTorch. We filled in the required__len__and__getitem__functions to return the size of the dataset and to add support the indexing of the dataset.from torch.utils.data import Dataset class FashionMNISTDataset(Dataset): def __init__(self, file_path, reshape_images): self.X, self.Y = load_data(file_path, reshape_images) def __len__(self): return len(self.X) def __getitem__(self, index): return self.X[index], self.Y[index]Similarly to the previous snippets of code:
>>> dataset= FashionMNISTDataset('dataset.csv', False) >>> print(dataset.X.shape) (20000, 784) >>> print(dataset.Y.shape) (20000,) >>> dataset= FashionMNISTDataset('dataset.csv', True) >>> print(dataset.X.shape) (20000, 1, 28, 28) >>> print(dataset.Y.shape) (20000,)This
FashionMNISTDatasetclass can be used bytorch.utils.data.DataLoader, which is a dataset iterator and that provides ways to batch the data, shuffle the data, or load the data in parallel. Here is a snippet of code that usestorch.utils.data.DataLoaderwithbatch_sizeset to 10:>>> dataset = FashionMNISTDataset('dataset.csv', False) >>> data_loader = torch.utils.data.DataLoader(dataset=dataset, batch_size=10, shuffle=False) >>> print(len(data_loader)) 2000 >>> images, labels = list(data_loader)[0] >>> print(type(images)) <class torch.LongTensor> >>> print(images) <class torch.LongTensor> 0 0 0 ... 25 9 0 0 0 0 ... 0 0 0 0 0 0 ... 0 0 0 ... ... ... 0 0 0 ... 0 0 0 0 0 0 ... 0 0 0 0 0 1 ... 0 0 0 [torch.LongTensor of size 10x784] >>> print(type(labels)) <class torch.LongTensor> >>> print(labels) 5 0 1 4 7 6 2 1 9 0 [torch.LongTensor of size 10]Note that we added the code to load the data with
torch.utils.data.DataLoaderin themain()function of the skeleton file. -
[90 points] For the next part of the assignment we give you a few functions that you are welcome to use and modify. They are:
-
The
train(model, data_loader, num_epochs, learning_rate)function, which accepts the following arguments- a
modelwhich is a subclass oftorch.nn.Module, - a
data_loaderwhich is a class oftorch.utils.data.DataLoader - two hyper-parameters:
num_epochsandlearning_rate. This function trains amodelfor the specifiednum_epochsusingtorch.nn.CrossEntropyLossloss function andtorch.optim.Adamas an optimizer. Once in a specified amount of iterations, the function prints the current loss, train accuracy, train F1-score for the model.
- a
-
The
evaluate(model, data_loader)function, which accepts- a
modelwhich is a subclass oftorch.nn.Module - a
data_loaderwhich is a class oftorch.utils.data.DataLoader.
The
evaluatefunction returns a list of actual labels and a list of predicted labels by thatmodelfor thisdata_loaderclass. This function can be used to get the metrics, such as accuracy or F1-score. - a
-
The
plot_confusion_matrix(cm, class_names, title=None)function, which visualises a confusion matrix. It accepts- a confusion matrix
cm, - a list of corresponding
class_names - an optional
title.
The
plot_confusion_matrixfunction was modified from here. - a confusion matrix
All you have to do is to fill in
__init__(self)andforward(self, x)for 3 different classes: Easy, Medium, and Advanced.-
[20 pts] Easy Model: In this part we ask you to fill in
__init__(self)andforward(self, x)of theEasyModelclass.EasyModelis a subclass oftorch.nn.Module, which is a base class for all neural network models in PyTorch. We ask you to build a model that consists of a single linear layer (usingtorch.nn.Linear). You will need to write one line of code. It starts withself.fc = torch.nn.Linear. It maps the size of the representation of an image to the number of classes. We recommend that you look at the API fortorch.nn.Check for yourself: what is the size of the representation of an image? How many output classes are there?
Once you have filled in
__init__(self)andforward(self, x)of theEasyModelclass you should expect something similar to this:>>> class_names = ['T-Shirt', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle Boot'] >>> num_epochs = 2 >>> batch_size = 100 >>> learning_rate = 0.001 >>> data_loader = torch.utils.data.DataLoader(dataset=FashionMNISTDataset('dataset.csv', False), batch_size=batch_size, shuffle=True) >>> easy_model = EasyModel() >>> train(easy_model, data_loader, num_epochs, learning_rate) Epoch : 0/2, Iteration : 49/200, Loss: 5.7422, Train Accuracy: 73.3450, Train F1 Score: 72.6777 Epoch : 0/2, Iteration : 99/200, Loss: 7.6222, Train Accuracy: 76.7650, Train F1 Score: 75.8522 Epoch : 0/2, Iteration : 149/200, Loss: 8.9238, Train Accuracy: 76.9600, Train F1 Score: 76.6251 Epoch : 0/2, Iteration : 199/200, Loss: 6.3722, Train Accuracy: 76.9450, Train F1 Score: 77.1084 Epoch : 1/2, Iteration : 49/200, Loss: 6.0220, Train Accuracy: 72.7300, Train F1 Score: 73.4246 Epoch : 1/2, Iteration : 99/200, Loss: 4.4724, Train Accuracy: 78.5450, Train F1 Score: 78.6831 Epoch : 1/2, Iteration : 149/200, Loss: 3.9865, Train Accuracy: 79.5950, Train F1 Score: 79.3139 Epoch : 1/2, Iteration : 199/200, Loss: 4.8550, Train Accuracy: 75.4150, Train F1 Score: 73.7432 >>> y_true_easy, y_pred_easy = evaluate(easy_model, data_loader) >>> print(f'Easy Model: ' f'Final Train Accuracy: {100.* accuracy_score(y_true_easy, y_pred_easy):.4f},', f'Final Train F1 Score: {100.* f1_score(y_true_easy, y_pred_easy, average="weighted"):.4f}') Easy Model: Final Train Accuracy: 75.4150, Final Train F1 Score: 73.7432 >>> plot_confusion_matrix(confusion_matrix(y_true_easy, y_pred_easy), class_names, 'Easy Model')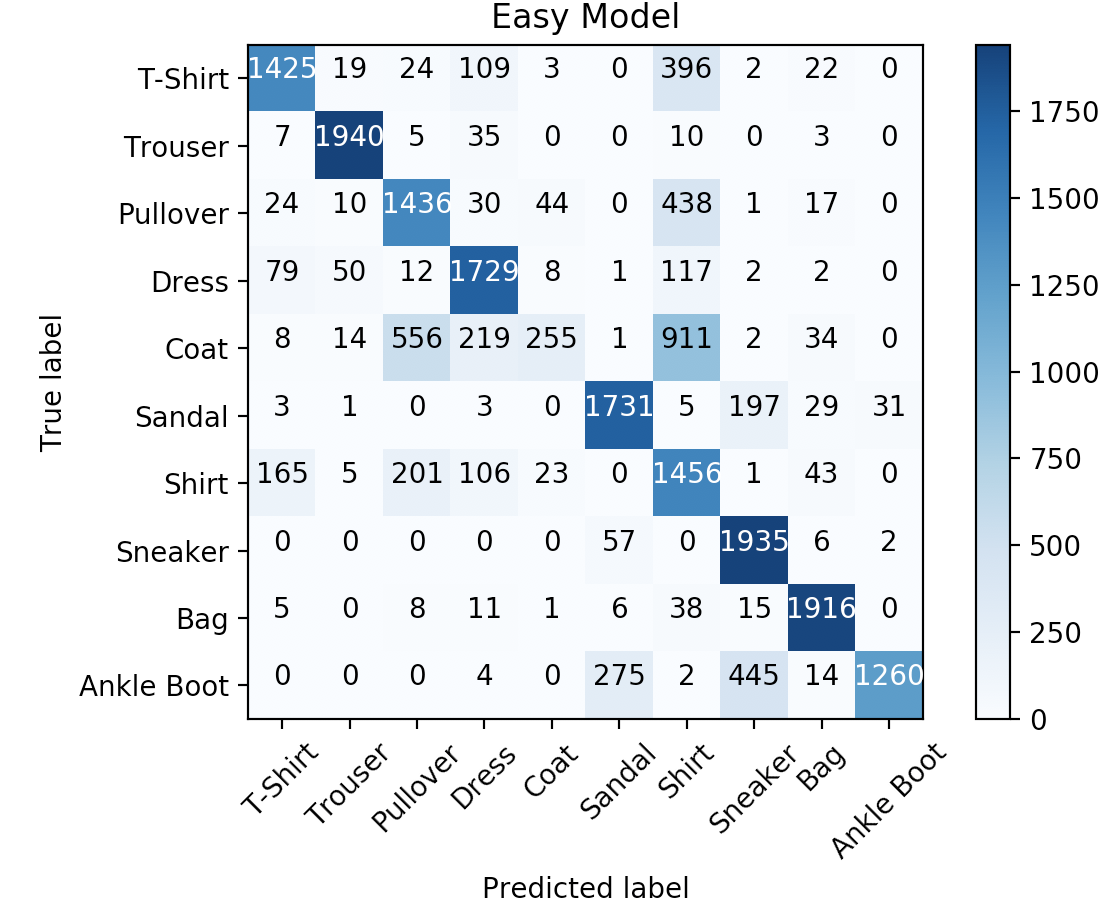
We reserved multiple datasets for testing with the same distribution of labels as given in
dataset.csv. We will train and evaluate your model on our end using the sametrain()andevaluate()functions as given. Full points will be given for anEasy Modelfor num_epochs = 2, batch_size = 100, learning_rate = 0.001 if the accuracy on the reserved datasets and F1-Score is >= 73%. -
[30 pts] Medium Model: In this part we ask you to fill in
__init__(self)andforward(self, x)of theMediumModelclass that is a subclass oftorch.nn.Module. We ask you to build a model that consists of a multiple fully-connected linear layers (usingtorch.nn.Linear). The network architecture is open-ended, so it is up to you to decide the number of linear layers and the size of nodes within the hidden layer(s). It can be difficult to get the intuition for a starting point, but the internet is a great resource. You might stumble across this blog post that gives a good solution for ourMediumclass by building a Fully-Connected Network with 2 hidden layers, e.g.:
Their architecture consists of an input layer that maps the size of the image as a 1D vector to a hidden layer of a smaller dimension. That first hidden layer is followed by another hidden layer of the same size. The second hidden layer is followed by the output layer, which should have a dimension that matches the number of output classes. The first and second hidden layers have reLU activation functions. The output layer is transformed using log softmax.
Try this architecture with different dimensions for the hidden layer. What works best, and what is worse? Does changing the activation function to tanh have a positive effect? How about adding another hidden layer?
Once you have filled in
__init__(self)andforward(self, x)of theMediumModelclass you should expect something similar to this:>>> class_names = ['T-Shirt', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle Boot'] >>> num_epochs = 2 >>> batch_size = 100 >>> learning_rate = 0.001 >>> data_loader = torch.utils.data.DataLoader(dataset=FashionMNISTDataset('dataset.csv', False), batch_size=batch_size, shuffle=True) >>> medium_model = MediumModel() >>> train(medium_model, data_loader, num_epochs, learning_rate) >>> y_true_medium, y_pred_medium = evaluate(medium_model, data_loader) Epoch : 0/2, Iteration : 49/200, Loss: 0.7257, Train Accuracy: 76.7000, Train F1 Score: 76.6240 Epoch : 0/2, Iteration : 99/200, Loss: 0.6099, Train Accuracy: 79.6000, Train F1 Score: 79.3427 Epoch : 0/2, Iteration : 149/200, Loss: 0.3406, Train Accuracy: 80.3550, Train F1 Score: 79.2653 Epoch : 0/2, Iteration : 199/200, Loss: 0.4423, Train Accuracy: 82.2350, Train F1 Score: 82.1259 Epoch : 1/2, Iteration : 49/200, Loss: 0.6591, Train Accuracy: 82.2450, Train F1 Score: 81.5656 Epoch : 1/2, Iteration : 99/200, Loss: 0.5055, Train Accuracy: 81.7150, Train F1 Score: 81.2029 Epoch : 1/2, Iteration : 149/200, Loss: 0.4616, Train Accuracy: 83.9600, Train F1 Score: 83.4397 Epoch : 1/2, Iteration : 199/200, Loss: 0.3895, Train Accuracy: 84.3500, Train F1 Score: 84.3794 >>> print(f'Medium Model: ' f'Final Train Accuracy: {100.* accuracy_score(y_true_medium, y_pred_medium):.4f},', f'Final F1 Score: {100.* f1_score(y_true_medium, y_pred_medium, average="weighted"):.4f}') Medium Model: Final Train Accuracy: 84.3500, Final F1 Score: 84.3794 >>> plot_confusion_matrix(confusion_matrix(y_true_medium, y_pred_medium), class_names, 'Medium Model')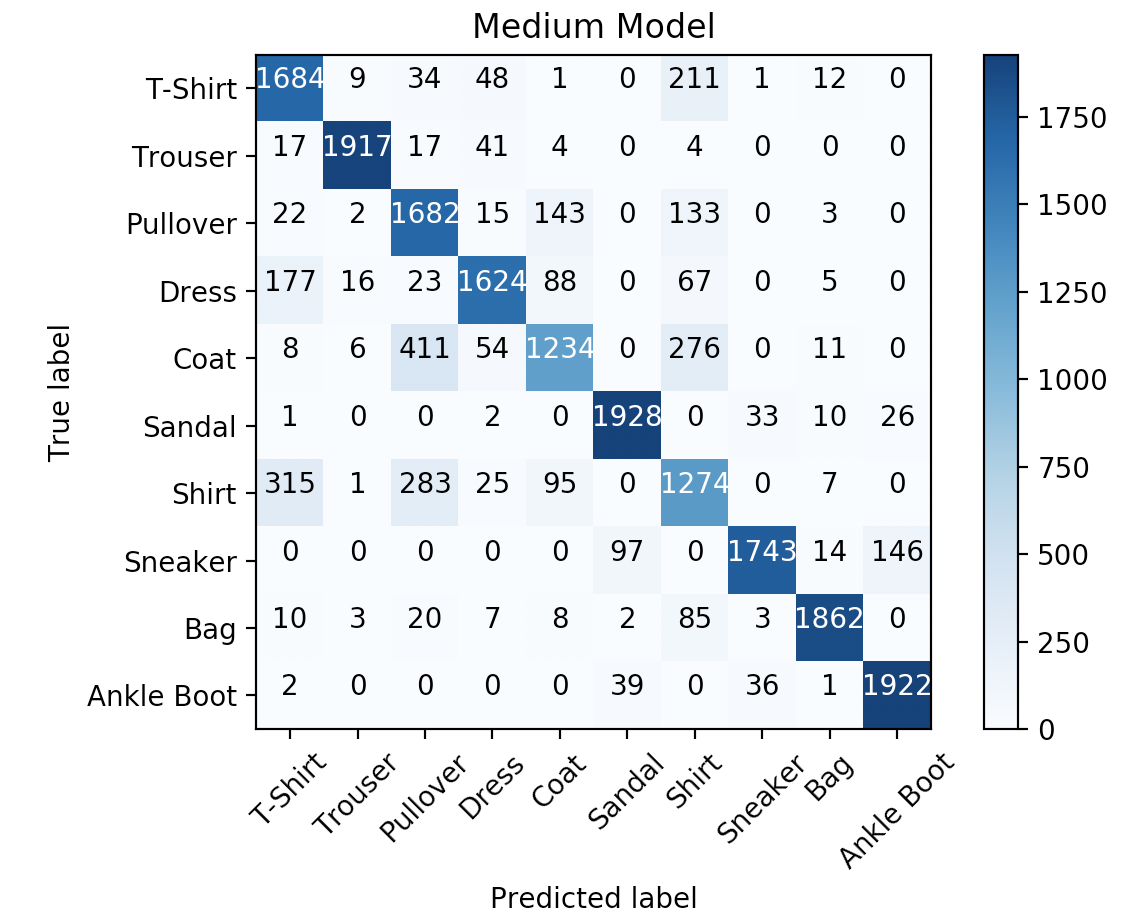
As before, we reserved multiple datasets for testing with the same distribution of labels as given in
dataset.csv. We will train and evaluate your model on our end using the sametrain()andevaluate()functions as given. Full points will be given for aMedium Modelfor num_epochs = 2, batch_size = 100, learning_rate = 0.001 if the accuracy on the reserved datasets and F1-Score is >= 82%. -
[40 pts] Advanced Model: In this part we ask you to fill in
__init__(self)andforward(self, x)of theAdvancedclass that is a subclass oftorch.nn.Module. We ask you to build a Convolutional Neural Network, which will consist of one or more convolutional layers (torch.nn.Conv2d) connected by the linear layers. Like in theMediumcase, the architecture is open-ended, so it is up to you to decide the number of layers, kernel size, activation functions etc. You can see performance of different architectures for this dataset here. The input to this model, unlike the input forEasyandMediumModels is expected to be different, and this is the reason why we asked you to reshape the images in Part 2.1. The output of this model remains the same as before.Here is an example of a potentially useful architecture:

The input image is on the left-hand side, which is a single \(28 \times 28\) image consisting of just one channel. The first transformation is a 2D Convolution that extracts 16 channels of information out of the original image using a \(5 \times 5\) kernel. These values are normalized over the channel dimension at the Batch Normalization step, preserving the dimensionality of the data. The normalized kernel values in each channel are then activated using reLU, and the dimensionality of the data is reduced using Max Pooling with a window size of \(2 x 2\), resulting in a reduction by \(50%\) in the size of the width and height dimensions. These pooled values are then reshaped into vector of \(16 * 14 * 14 = 3136\) values, which are then used as a Linear layer that map down to a vector of \(10\) values, representing the possible output labels.
Here is a sample of how to build a model with this architecture:
def __init__(self): ... conv_layer = torch.nn.Sequential( torch.nn.Conv2d(1, 16, kernel_size=5, padding=2), torch.nn.BatchNorm2d(16), torch.nn.ReLU(), torch.nn.MaxPool2d(2) ) forward_layer = torch.nn.Linear(14 * 14 * 32, 10) ... def forward(self, x): x = self.conv_layer(x) x = x.view(x.size(0), -1) // coerce into the right shape x = self.forward_layer(x) return xThis model is OK, but might not hit the thresholds we’re looking for. Experiment with the following ideas to get your
AdvancedModelup to an F1 score of 88% or higher.- Add another convolution layer between the current one and the forward layer. You can use the same basic structure, but try adding or taking away channels at the 2D Convolution step.
- Try a different activation function
- Do an average pooling calculation instead of max pooling.
Any architecture that reaches the F1 threshold is fine. You might find success with just a small change. If you’re stuck, make sure that you just try one of these suggestions at a time. Pay careful attention to your dimensionality.
Once you have filled in
__init__(self)andforward(self, x)of theAdvancedModelclass you can use the following to see the performance of your model.>>> class_names = ['T-Shirt', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle Boot'] >>> num_epochs = 2 >>> batch_size = 100 >>> learning_rate = 0.001 >>> data_loader_reshaped = torch.utils.data.DataLoader(dataset=FashionMNISTDataset('dataset.csv', True), batch_size=batch_size, shuffle=True) >>> advanced_model = AdvancedModel() >>> train(advanced_model, data_loader_reshaped, num_epochs, learning_rate) >>> y_true_advanced, y_pred_advanced = evaluate(advanced_model, data_loader_reshaped) Epoch : 0/2, Iteration : 49/200, Loss: 0.7043, Train Accuracy: 80.2100, Train F1 Score: 79.9030 Epoch : 0/2, Iteration : 99/200, Loss: 0.4304, Train Accuracy: 84.0650, Train F1 Score: 83.9004 Epoch : 0/2, Iteration : 149/200, Loss: 0.4911, Train Accuracy: 85.0850, Train F1 Score: 84.4854 Epoch : 0/2, Iteration : 199/200, Loss: 0.3728, Train Accuracy: 86.9900, Train F1 Score: 86.9663 Epoch : 1/2, Iteration : 49/200, Loss: 0.3628, Train Accuracy: 87.2150, Train F1 Score: 86.9041 Epoch : 1/2, Iteration : 99/200, Loss: 0.3961, Train Accuracy: 87.7100, Train F1 Score: 87.7028 Epoch : 1/2, Iteration : 149/200, Loss: 0.3038, Train Accuracy: 88.9200, Train F1 Score: 88.9186 Epoch : 1/2, Iteration : 199/200, Loss: 0.3445, Train Accuracy: 89.2500, Train F1 Score: 88.8764 >>> print(f'Advanced Model: ' f'Final Train Accuracy: {100.* accuracy_score(y_true_advanced, y_pred_advanced):.4f},', f'Final F1 Score: {100.* f1_score(y_true_advanced, y_pred_advanced, average="weighted"):.4f}') Advanced Model: Final Train Accuracy: 89.2500, Final F1 Score: 88.8764 plot_confusion_matrix(confusion_matrix(y_true_advanced, y_pred_advanced), class_names, 'Advanced Model')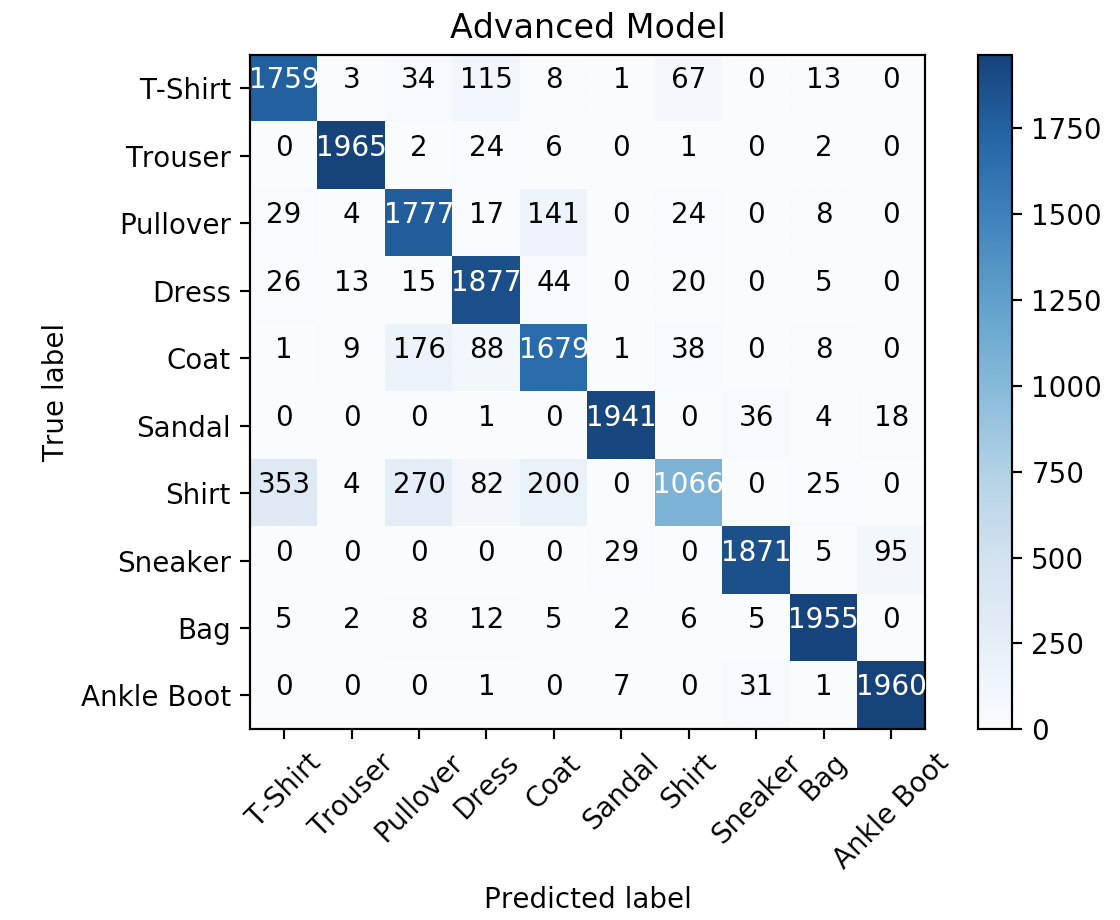
As before, we reserved multiple datasets for testing with the same distribution of labels as given in
dataset.csv. We will train and evaluate your model on our end using the sametrain()andevaluate()functions as given. Full points will be given for aAdvanced Modelfor num_epochs = 2, batch_size = 100, learning_rate = 0.001 if the accuracy on the reserved datasets and F1-Score is >= 88%.
-
3. Feedback [5 points]
-
[1 points] What were the two classes that one of your models confused the most?
-
[1 points] Describe your architecture for the Advanced Model.
-
[1 point] Approximately how many hours did you spend on this assignment?
-
[1 point] Which aspects of this assignment did you find most challenging? Were there any significant stumbling blocks?
-
[1 point] Which aspects of this assignment did you like? Is there anything you would have changed?